AvatarFusion: Zero-shot Generation of Clothing-Decoupled 3D Avatars Using 2D Diffusion
|
|
|
|
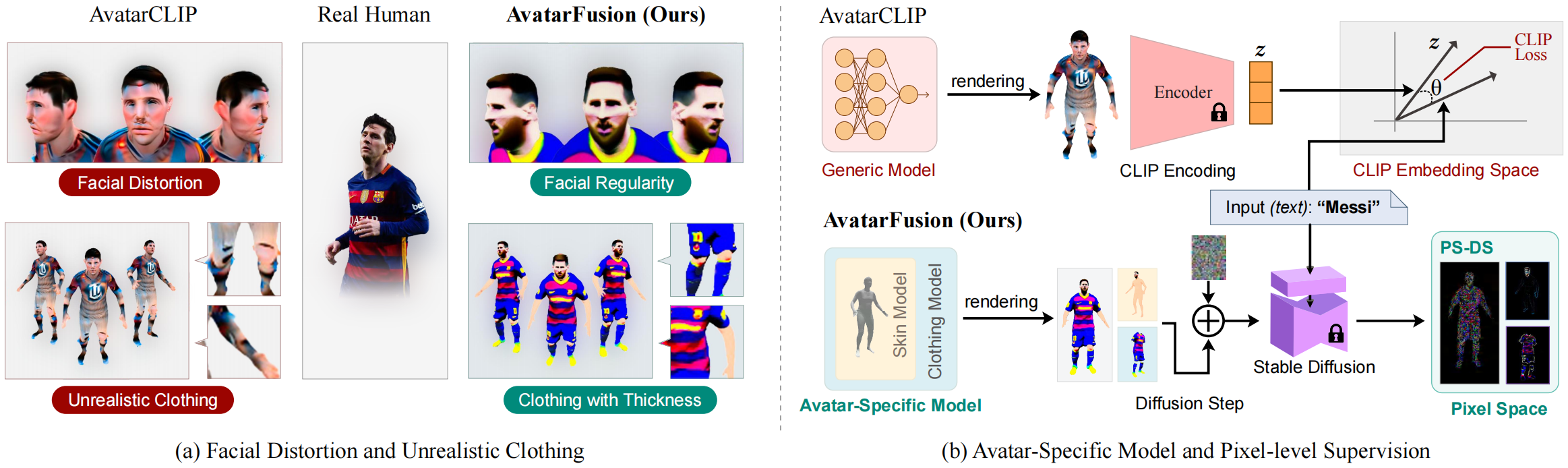
Large-scale pre-trained vision-language models allow for the zero-shot text-based generation of 3D avatars. The previous state-of-the-art method utilized CLIP to supervise neural implicit models that reconstructed a human body mesh. However, this approach has two limitations. Firstly, the lack of avatar-specific models can cause facial distortion and unrealistic clothing in the generated avatars. Secondly, CLIP only provides optimization direction for the overall appearance, resulting in less impressive results. To address these limitations, we propose AvatarFusion, the first framework to use a latent diffusion model to provide pixel-level guidance for generating human-realistic avatars while simultaneously segmenting clothing from the avatar's body. AvatarFusion includes the first clothing-decoupled neural implicit avatar model that employs a novel Dual Volume Rendering strategy to render the decoupled skin and clothing sub-models in one space. We also introduce a novel optimization method, called Pixel-Semantics Difference-Sampling (PS-DS), which semantically separates the generation of body and clothes, and generates a variety of clothing styles. Moreover, we establish the first benchmark for zero-shot text-to-avatar generation. Our experimental results demonstrate that our framework outperforms previous approaches, with significant improvements observed in all metrics. Additionally, since our model is clothing-decoupled, we can exchange the clothes of avatars.
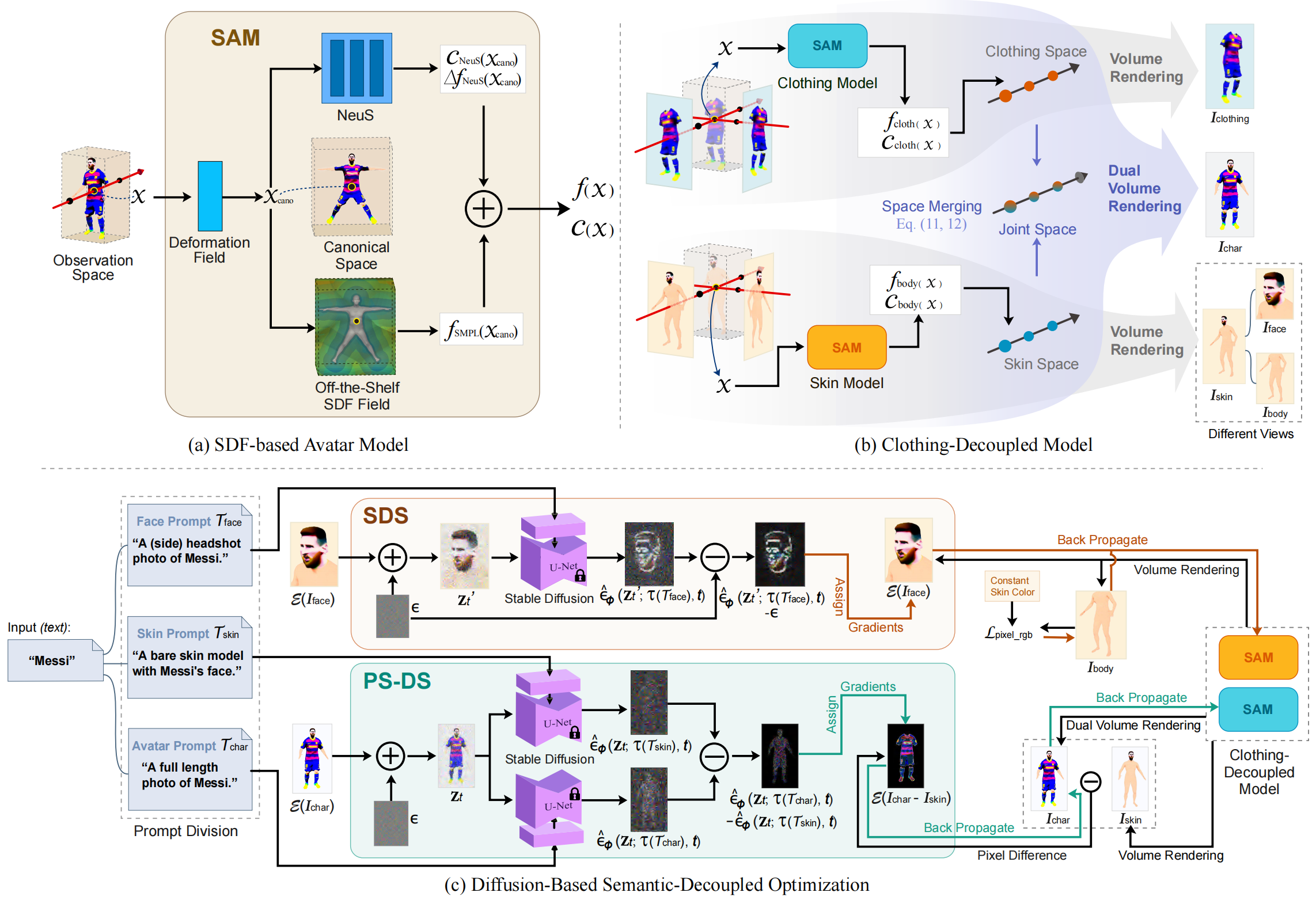
Overview of AvatarFusion. The upper left part shows (a) the SDF-Based Avatar Model (SAvM) which takes a point $\mathbf{x}$ as input, and output its SDF value and color value. The upper right part shows (b) the clothing-decoupled model, which takes two SAvMs representing skin and clothing, and merge the space to render avatars with clothes. The lower part shows (c) our diffusion-based optimization methods with PS-DS separating the clothing from skin semantically. For clarity, we omit the image encoder $\mathcal{E}$ in the figure.
|
Stable DreamFusion |
Latent-NeRF |
AvatarCLIP |
AvatarFusion(Ours) |

|

|
|

|

|

|
|

|
.png)
|

|
|

|
.png)
|

|
|

|

|

|
|

|

|

|
|

|

|

|
|

|

|

|
|

|

|

|

|

|

|

|

|

|

|